作為內容創作者或部落格作者,您獨特的高品質內容是您的資產。但您是否注意到,一些生成式人工智慧平台(例如 OpenAI 和 CCBot)可能會在未經您同意的情況下使用您的工作來訓練他們的演算法?
您不必擔心!透過使用一個名為的簡單文件 機器人.txt,您可以阻止這些AI爬蟲訪問您的網站或部落格。
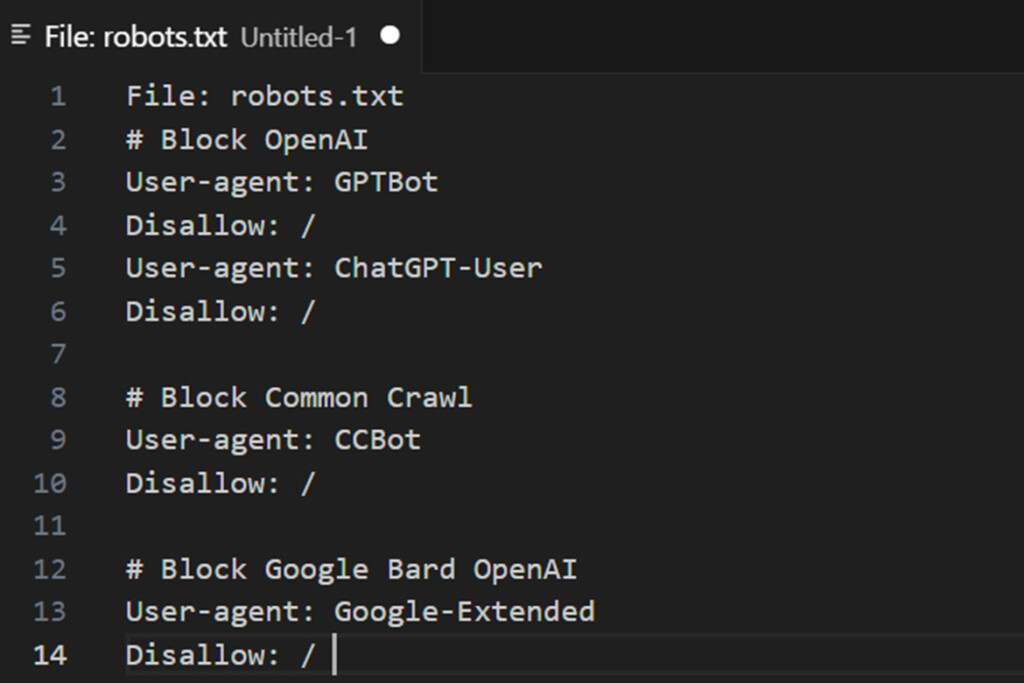
什麼是 robots.txt 檔案?
這 機器人.txt 文件是一種工具,允許網站所有者管理搜尋引擎爬蟲與其內容互動的方式。它使您能夠禁止特定機器抓取您的網站,從而確保更好地控制您的內容。
下面的語法顯示如何使用使用者代理程式阻止單一機器人:
使用者代理:{BOT-NAME-HERE} 不允許:/下面顯示如何允許特定機器人使用使用者代理程式抓取您的網站:
使用者代理:{BOT-NAME-HERE} 允許:/將 robots.txt 檔案放置在哪裡?
將文件上傳到您網站的根資料夾:
https://example.com/robots.txt https://blog.example.com/robots.txt了解更多 機器人.txt
如果您準備好控制網站的可訪問性,請更深入地了解以下詳細信息 機器人.txt 有了這些有用的資源:
- robots.txt簡介 by Google:了解基本原理
機器人.txt工作原理以及如何為您的網站有效配置它。 - 什麼是 robots.txt? | robots.txt 檔案的工作原理 來自 Cloudflare:目的和功能的綜合指南
機器人.txt管理網路爬蟲存取。
如何使用 robots.txt 檔案阻止 AI 爬蟲機器人
文法:
使用者代理:{AI-Crawlers-Bot-Name-Here} 不允許:/阻止 Google AI(Bard 和 Vertex AI 產生 API)
將以下兩行加入 robots.txt 中:
用戶代理:Google 擴充禁止:/有關用戶代理和人工智慧機器人的附加資訊
有關管理爬蟲的更多信息,您可以查看 使用者代理列表 由 Google 抓取工具和抓取工具使用。這可以幫助您識別造訪您網站的合法 Google 機器人。
然而,值得注意的是:
- Google 不提供 CIDR、IP 範圍或 ASN 詳細信息 其人工智慧機器人,使得透過網路伺服器防火牆直接阻止它們變得具有挑戰性。
- 結果,使用
機器人.txt文件仍然是指導合規爬蟲和限制對內容的存取的最有效方法之一。
為了進行進階控制,監視伺服器日誌是否有異常活動並配置其他安全措施,例如速率限製或 IP 阻止,以補充您的 機器人.txt 指令。
使用 robots.txt 檔案阻止 OpenAI
將以下四行加入 robots.txt 中:
使用者代理:GPTBot 禁止:/ 使用者代理:ChatGPT-使用者禁止:/OpenAI 使用兩種不同的使用者代理程式進行操作:一種用於網路爬行,另一種用於瀏覽,每個代理程式都與唯一的 CIDR 和 IP 位址範圍相關聯。配置防火牆規則來阻止這些需要對網路概念和對 Linux 伺服器的根級存取有深入的了解。
如果您不熟悉這些技術方面(例如管理 CIDR 範圍或配置防火牆),建議尋求 Linux 系統管理員的協助。請記住,OpenAI 的 IP 位址範圍可能會發生變化,這可能會將這一過程變成持續不斷的努力以跟上更新——一場貓捉老鼠的遊戲。
1:ChatGPT-User 由下列人員使用 外掛 在 ChatGPT 中
下面是一個列表 OpenAI 的爬蟲和取得器使用的使用者代理程式及其關聯的 CIDR 或 IP 位址範圍。要阻止 OpenAI 的插件 AI 機器人,您可以配置 Web 伺服器防火牆以限制來自特定 IP 範圍的訪問,例如 23.98.142.176/28.
以下是如何使用以下命令阻止 CIDR 或 IP 範圍的範例 烏夫沃 命令或 iptables 在您的伺服器上:
使用UFW:
sudo ufw 拒絕來自 23.98.142.176/28 使用 iptables:
sudo iptables -A 輸入 -s 23.98.142.176/28 -j 刪除 這些命令可防止來自指定 IP 範圍的任何流量存取您的伺服器。請務必定期檢查和更新您的防火牆規則,以適應 OpenAI IP 範圍的變更。如果您不熟悉設定防火牆,請考慮尋求 Linux 系統管理員的協助。
2:GPTBot由ChatGPT使用
下面是一個列表 OpenAI 爬蟲和獲取器使用的使用者代理的數量,以及關聯的 CIDR 或 IP 位址範圍。您可以使用下列任一方法直接在 Web 伺服器上封鎖這些範圍 烏夫沃 命令或 iptables.
以下是封鎖這些 CIDR 範圍的 shell 腳本範例:
用於阻止 OpenAI CIDR 範圍的 Shell 腳本
#!/bin/bash # 目的:阻止 OpenAI ChatGPT 機器人 CIDR # 測試環境:Debian 和 Ubuntu Linux # --------------------------- --------------------------------------- file="/tmp/out.txt.$$ " wget -q -O "$file" https://openai.com/gptbot-ranges.txt 2>/dev/null while IFS= read -r cidr do sudo ufw拒絕從$cidr到任何連接埠80的原始tcp sudo ufw拒絕從 $cidr 到任何連接埠 443 的原始 TCP 完成 < "$file" [ -f "$file" ] && rm -f "$file"如果您不熟悉防火牆配置,請諮詢 Linux 系統管理員以取得協助。定期使用新範圍更新腳本,以跟上 OpenAI IP 清單的變更。
使用 robots.txt 檔案阻止 commoncrawl (CCBot)
將以下兩行加入 robots.txt 中:
使用者代理:CCBot 禁止:/Common Crawl 是一個非營利基金會,經營一個名為 CCBot 的機器人,該機器人廣泛用於收集用於訓練人工智慧模型的資料。如果您想防止您的內容以這種方式被利用,那麼阻止 CCBot 也很重要。然而,與 Google 類似,Common Crawl 不提供 CIDR、IP 位址範圍或自治系統資訊 (ASN),這些資訊可用於阻止其機器人通過 Web 伺服器防火牆。這種限制使得在網路層級限制他們的存取變得具有挑戰性。
使用 robots.txt 檔案阻止 Perplexity AI
另一個使用生成式人工智慧重寫內容的服務是 PerplexityBot。若要封鎖此機器人,您可以將以下規則新增至您的 機器人.txt file:
使用者代理:PerplexityBot 禁止:/ 此外,PerplexityBot 也發布了其 IP 位址範圍,您可以使用 Web 應用程式防火牆 (WAF) 或 Web 伺服器防火牆來封鎖。這確保了額外的保護層,防止未經授權的存取您的內容。
阻止人為人工智慧(克勞德)
將以下行新增至您的 robots.txt 檔案:
使用者代理:anthropic-ai 禁止:/ 使用者代理程式:Claude-Web 禁止:/ 使用者代理:ClaudeBot 禁止:/人工智慧機器人可以忽略我的嗎 機器人.txt 文件?
人工智慧機器人可以忽略我的嗎 機器人.txt 文件?
像 Google 和 OpenAI 這樣的知名組織通常會尊重 機器人.txt 協議並遵守您設定的規則。然而,一些設計不良或惡意的人工智慧機器人可能會選擇忽略你的 機器人.txt 完全文件,繞過這些限制並未經授權存取您的內容。
阻止人工智慧機器人使用您的數據是否符合道德?
圍繞人工智慧訓練資料的道德困境很複雜。雖然人工智慧經常被宣傳為造福人類的工具,促進醫學和科學等領域的進步,但許多人對 OpenAI、Google或微軟等公司的真實意圖表示懷疑。有些人認為,這些技術更注重利潤而不是利他主義,特別是當生成式人工智慧開始取代白領工作時。
值得注意的是,透過選項控制訪問 機器人.txt 僅在作者和公司在法庭上對這些做法提出訴訟後才可用。最終,保護您的工作成果是個人決定,權衡與人工智慧系統共享工作成果的潛在好處和風險非常重要。