作为内容创作者或博客作者,您独特、高质量的内容是您的资产。但您是否注意到,一些生成式人工智能平台(如 OpenAI 和 CCBot)可能会在未经您同意的情况下使用您的作品来训练他们的算法?
你不必担心!通过使用一个名为 robots.txt,您可以阻止这些AI爬虫访问您的网站或博客。
什么是 robots.txt 文件?
这 robots.txt 文件是一种工具,允许网站所有者管理搜索引擎爬虫如何与其内容交互。它使您能够禁止特定机器人爬取您的网站,从而确保更好地控制您的内容。
以下语法显示如何使用用户代理阻止单个机器人:
用户代理:{BOT-NAME-HERE} 禁止:/下面展示了如何允许特定的机器人使用用户代理来抓取您的网站:
用户代理:{BOT-NAME-HERE} 允许:/您的 robots.txt 文件应该放在哪里?
将文件上传到您的网站的根文件夹:
https://example.com/robots.txt https://blog.example.com/robots.txt详细了解 robots.txt
如果你已经准备好控制网站的可访问性,请深入了解 robots.txt 利用这些有用的资源:
- robots.txt 简介 谷歌:了解基础知识
robots.txt工作原理以及如何为您的网站进行有效的配置。 - 什么是 robots.txt?| robots.txt 文件的工作原理 来自 Cloudflare:关于
robots.txt管理网络爬虫访问。
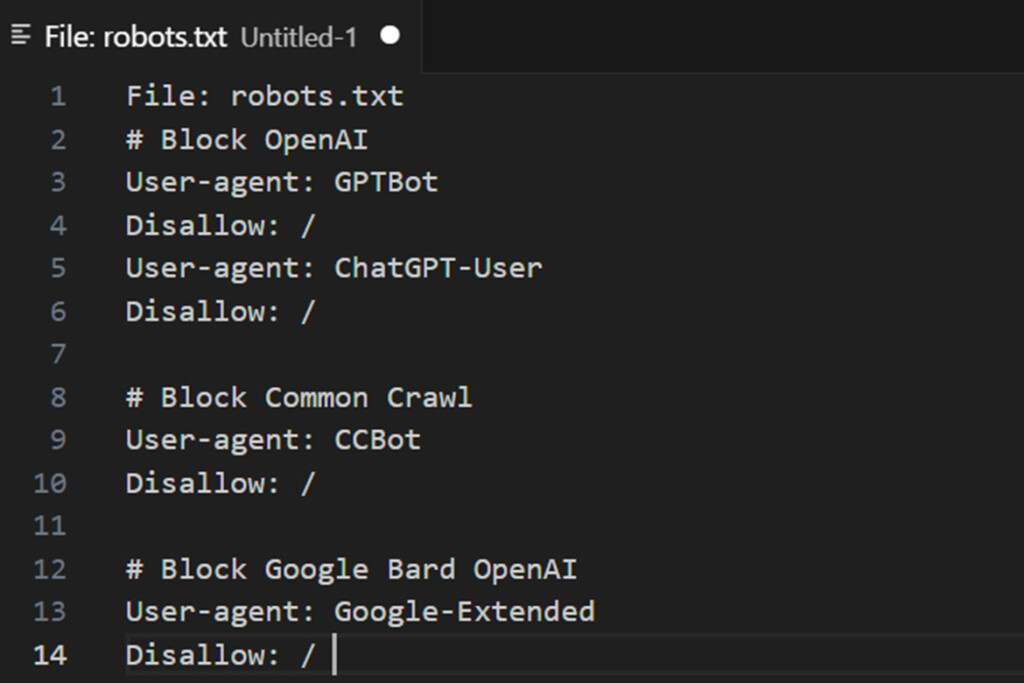
如何使用 robots.txt 文件阻止 AI 爬虫机器人
语法:
用户代理:{AI-Crawlers-Bot-Name-Here} 禁止:/阻止 Google AI(Bard 和 Vertex AI 生成 API)
将以下两行添加到您的 robots.txt:
用户代理:Google-Extended 禁止:/有关用户代理和人工智能机器人的其他信息
有关管理爬虫的更多信息,您可以查看 用户代理列表 由 Google 抓取工具和提取工具使用。这可以帮助您识别访问您网站的合法 Google 机器人。
但需要注意的是:
- Google 不提供 CIDR、IP 范围或 ASN 详细信息 针对其 AI 机器人,因此很难通过您的 Web 服务器防火墙直接阻止它们。
- 因此,使用
robots.txt文件仍然是引导合规爬虫并限制对您的内容的访问的最有效方法之一。
对于高级控制,请监视服务器日志中是否存在异常活动,并配置其他安全措施(如速率限制或 IP 阻止),以补充您的 robots.txt 指令。
使用 robots.txt 文件阻止 OpenAI
将以下四行添加到您的 robots.txt:
用户代理:GPTBot 不允许:/ 用户代理:ChatGPT-User 不允许:/OpenAI 使用两个不同的用户代理进行操作:一个用于网络爬取,另一个用于浏览,每个代理都与唯一的 CIDR 和 IP 地址范围相关联。配置防火墙规则以阻止这些操作需要对网络概念有深入的了解,并且需要对 Linux 服务器具有根级访问权限。
如果您不熟悉这些技术方面,例如管理 CIDR 范围或配置防火墙,建议寻求 Linux 系统管理员的帮助。请记住,OpenAI 的 IP 地址范围可能会发生变化,这可能会使这个过程变成一项持续不断的努力以跟上更新——一场猫捉老鼠的游戏。
1:ChatGPT-User 由 插件 在 ChatGPT 中
以下是列表 OpenAI 的爬虫和抓取器使用的用户代理,以及其关联的 CIDR 或 IP 地址范围。要阻止 OpenAI 的插件 AI 机器人,您可以配置 Web 服务器防火墙以限制特定 IP 范围的访问,例如 23.98.142.176/28.
以下是如何使用以下示例来阻止 CIDR 或 IP 范围 联邦快递 命令或 iptables 在您的服务器上:
使用UFW:
sudo ufw 拒绝来自 23.98.142.176/28 使用 iptables:
sudo iptables -A 输入 -s 23.98.142.176/28 -j DROP 这些命令可阻止来自指定 IP 范围的任何流量访问您的服务器。请务必定期检查和更新防火墙规则,以适应 OpenAI 的 IP 范围的变化。如果您不熟悉如何配置防火墙,请考虑寻求 Linux 系统管理员的帮助。
2:GPTBot 由 ChatGPT 使用
以下是列表 OpenAI 爬虫和抓取器使用的用户代理,以及相关的 CIDR 或 IP 地址范围。您可以使用以下方式直接在 Web 服务器上阻止这些范围: 联邦快递 命令或 iptables.
以下是阻止这些 CIDR 范围的示例 shell 脚本:
用于阻止 OpenAI CIDR 范围的 Shell 脚本
#!/bin/bash # 目的:阻止 OpenAI ChatGPT 机器人 CIDR # 已在以下平台上测试:Debian 和 Ubuntu Linux # ------------------------------------------------------------------ file="/tmp/out.txt.$$" wget -q -O "$file" https://openai.com/gptbot-ranges.txt 2>/dev/null while IFS= read -r cidr do sudo ufw 拒绝从 $cidr 到任何端口 80 的 proto tcp sudo ufw 拒绝从 $cidr 到任何端口 443 的 proto tcp done < "$file" [ -f "$file" ] && rm -f "$file"如果您不熟悉防火墙配置,请咨询 Linux 系统管理员寻求帮助。定期使用新范围更新脚本,以跟上 OpenAI 的 IP 列表的变化。
使用 robots.txt 文件阻止 commoncrawl (CCBot)
将以下两行添加到您的 robots.txt:
用户代理:CCBot 禁止:/非营利基金会 Common Crawl 运营着一个名为 CCBot 的机器人,该机器人被广泛用于收集数据以训练 AI 模型。如果您想防止您的内容被以这种方式利用,阻止 CCBot 也是必不可少的。但是,与 Google 类似,Common Crawl 不提供 CIDR、IP 地址范围或自治系统信息 (ASN),这些信息可用于阻止其机器人通过您的 Web 服务器防火墙。这种限制使得在网络级别限制它们的访问变得具有挑战性。
使用 robots.txt 文件阻止 Perplexity AI
另一项使用生成式 AI 重写内容的服务是 PerplexityBot。要阻止此机器人,您可以将以下规则添加到您的 robots.txt file:
用户代理:PerplexityBot 禁止:/ 此外,PerplexityBot 还发布了其 IP 地址范围,您可以使用 Web 应用程序防火墙 (WAF) 或 Web 服务器防火墙进行阻止。这可确保为您的内容提供额外的保护,防止未经授权的访问。
阻止人智人工智能 (Claude)
将以下行添加到您的 robots.txt 文件:
用户代理:anthropic-ai 禁止:/ 用户代理:Claude-Web 禁止:/ 用户代理:ClaudeBot 禁止:/人工智能机器人可以忽略我的 robots.txt 文件?
人工智能机器人可以忽略我的 robots.txt 文件?
像谷歌和 OpenAI 这样的知名组织通常尊重 robots.txt 协议并遵守你设置的规则。然而,一些设计不良或恶意的人工智能机器人可能会选择忽略你的 robots.txt 文件,绕过这些限制并在未经授权的情况下访问您的内容。
阻止人工智能机器人使用您的数据是否合乎道德?
围绕人工智能训练数据的道德困境非常复杂。虽然人工智能经常被宣传为改善人类的工具,推动医学和科学等领域的进步,但许多人对 OpenAI、谷歌或微软等公司的真实意图表示怀疑。一些人认为,这些技术更注重利润而不是利他主义,尤其是在生成式人工智能开始取代白领工作的情况下。
值得注意的是,通过 robots.txt 只有在作者和公司提起诉讼挑战这些做法后,这项技术才得以实现。归根结底,保护你的作品是一个个人决定,重要的是要权衡与人工智能系统共享作品的潜在利益和风险。