Sebagai pencipta kandungan atau pengarang blog, kandungan unik dan berkualiti tinggi anda adalah aset anda. Tetapi adakah anda perasan bahawa beberapa platform AI generatif, seperti OpenAI dan CCBot, mungkin menggunakan kerja anda untuk melatih algoritma mereka—tanpa persetujuan anda?
Anda tidak perlu risau! Dengan menggunakan fail ringkas yang dipanggil robots.txt, anda boleh menyekat perangkak AI ini daripada mengakses tapak web atau blog anda.
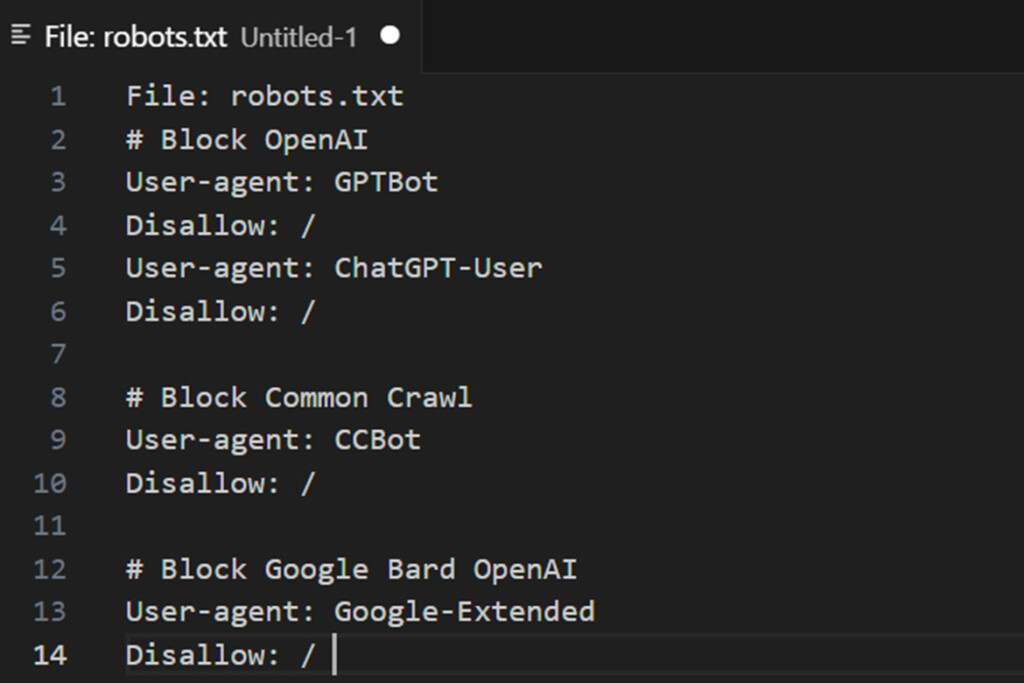
Apakah fail robots.txt?
The robots.txt fail ialah alat yang membolehkan pemilik tapak web mengurus cara perangkak enjin carian berinteraksi dengan kandungan mereka. Ia memberi anda kuasa untuk tidak membenarkan bot tertentu daripada merangkak tapak anda, memastikan kawalan yang lebih besar ke atas kandungan anda.
Sintaks di bawah menunjukkan cara menyekat bot tunggal menggunakan ejen pengguna:
ejen pengguna: {BOT-NAME-HERE} tidak membenarkan: /Di bawah menunjukkan cara membenarkan bot tertentu merangkak tapak web anda menggunakan ejen pengguna:
Ejen pengguna: {BOT-NAME-HERE} Benarkan: /Di mana untuk meletakkan fail robots.txt anda?
Muat naik fail ke folder akar tapak web anda:
https://example.com/robots.txt https://blog.example.com/robots.txtKetahui Lebih Lanjut Mengenai robots.txt
Jika anda sudah bersedia untuk mengawal kebolehaksesan tapak web anda, selami lebih mendalam butirannya robots.txt dengan sumber yang berguna ini:
- Pengenalan kepada robots.txt oleh Google: Fahami asas bagaimana
robots.txtberfungsi dan cara mengkonfigurasinya dengan berkesan untuk tapak anda. - Apakah robots.txt? | Cara fail robots.txt berfungsi daripada Cloudflare: Panduan komprehensif untuk tujuan dan fungsi
robots.txtdalam menguruskan akses perangkak web.
Cara menyekat bot perangkak AI menggunakan fail robots.txt
Sintaksnya:
ejen pengguna: {AI-Crawlers-Bot-Name-Here} tidak membenarkan: /Menyekat Google AI (API generatif AI Bard dan Vertex)
Tambahkan dua baris berikut pada robots.txt anda:
Ejen pengguna: Google-Extended Disallow: /Maklumat Tambahan tentang Ejen Pengguna dan Bot AI
Untuk mendapatkan maklumat lanjut tentang mengurus perangkak, anda boleh menyemak senarai ejen pengguna digunakan oleh perangkak dan pengambil Google. Ini boleh membantu anda mengenal pasti bot Google yang sah yang mengakses tapak anda.
Walau bagaimanapun, adalah penting untuk diperhatikan bahawa:
- Google tidak memberikan butiran CIDR, julat IP atau ASN untuk bot AInya, menjadikannya mencabar untuk menyekatnya terus melalui tembok api pelayan web anda.
- Akibatnya, menggunakan a
robots.txtfail kekal sebagai salah satu kaedah paling berkesan untuk membimbing perangkak yang patuh dan menyekat akses kepada kandungan anda.
Untuk kawalan lanjutan, pantau log pelayan anda untuk aktiviti luar biasa dan konfigurasikan langkah keselamatan tambahan, seperti pengehadan kadar atau penyekatan IP, untuk melengkapkan anda robots.txt arahan.
Menyekat OpenAI menggunakan fail robots.txt
Tambahkan empat baris berikut pada robots.txt anda:
Ejen pengguna: GPTBot Disallow: / User-agent: ChatGPT-User Disallow: /OpenAI menggunakan dua ejen pengguna yang berbeza untuk operasinya: satu untuk merangkak web dan satu lagi untuk menyemak imbas, masing-masing dikaitkan dengan julat alamat CIDR dan IP yang unik. Mengkonfigurasi peraturan tembok api untuk menyekat ini memerlukan pemahaman lanjutan tentang konsep rangkaian dan akses peringkat akar kepada pelayan Linux.
Jika anda tidak biasa dengan aspek teknikal ini, seperti mengurus julat CIDR atau mengkonfigurasi tembok api, anda dinasihatkan untuk mendapatkan bantuan pentadbir sistem Linux. Perlu diingat bahawa julat alamat IP OpenAI tertakluk kepada perubahan, yang boleh mengubah proses ini menjadi usaha berterusan untuk mengikuti kemas kini—permainan kucing dan tetikus.
1: Pengguna ChatGPT digunakan oleh pemalam dalam ChatGPT
Di bawah adalah senarai ejen pengguna yang digunakan oleh perangkak dan pengambil OpenAI, bersama-sama dengan julat alamat CIDR atau IP yang berkaitan. Untuk menyekat bot AI pemalam OpenAI, anda boleh mengkonfigurasi tembok api pelayan web anda untuk menyekat akses daripada julat IP tertentu, seperti 23.98.142.176/28.
Berikut ialah contoh cara untuk menyekat julat CIDR atau IP menggunakan ufw perintah atau iptables pada pelayan anda:
Menggunakan UFW:
sudo ufw menafikan daripada 23.98.142.176/28 Menggunakan iptables:
sudo iptables -A INPUT -s 23.98.142.176/28 -j DROP Perintah ini menghalang sebarang trafik yang berasal dari julat IP yang ditentukan daripada mengakses pelayan anda. Pastikan anda menyemak dan mengemas kini peraturan tembok api anda secara berkala untuk mengambil kira perubahan dalam julat IP OpenAI. Jika anda tidak biasa dengan mengkonfigurasi tembok api, pertimbangkan untuk mendapatkan bantuan pentadbir sistem Linux.
2: GPTBot digunakan oleh ChatGPT
Di bawah adalah senarai ejen pengguna yang digunakan oleh perangkak dan pengambil OpenAI, bersama-sama dengan julat alamat CIDR atau IP yang berkaitan. Anda boleh menyekat julat ini terus pada pelayan web anda menggunakan sama ada ufw perintah atau iptables.
Berikut ialah contoh skrip shell untuk menyekat julat CIDR tersebut:
Skrip Shell untuk Menyekat Julat CIDR OpenAI
#!/bin/bash # Tujuan: Sekat OpenAI ChatGPT bot CIDR # Diuji pada: Debian dan Ubuntu Linux # -------------------------- --------------------------------------- file="/tmp/out.txt.$$ " wget -q -O "$file" https://openai.com/gptbot-ranges.txt 2>/dev/null manakala IFS= baca -r cidr lakukan sudo ufw menafikan proto tcp daripada $cidr ke mana-mana port 80 sudo ufw menafikan proto tcp daripada $cidr ke mana-mana port 443 selesai < "$file" [ -f "$file" ] && rm -f "$file"Jika anda tidak biasa dengan konfigurasi tembok api, rujuk pentadbir sistem Linux untuk mendapatkan bantuan. Kemas kini skrip dengan julat baharu secara kerap untuk mengikuti perubahan dalam senarai IP OpenAI.
Menyekat commoncrawl (CCBot) menggunakan fail robots.txt
Tambahkan dua baris berikut pada robots.txt anda:
Ejen pengguna: CCBot Disallow: /Common Crawl, sebuah yayasan bukan untung, mengendalikan bot yang dipanggil CCBot, yang digunakan secara meluas untuk mengumpul data untuk melatih model AI. Menyekat CCBot juga penting jika anda ingin menghalang kandungan anda daripada digunakan dengan cara ini. Walau bagaimanapun, sama seperti Google, Common Crawl tidak menyediakan CIDR, julat alamat IP atau maklumat sistem autonomi (ASN) yang boleh digunakan untuk menyekat botnya melalui tembok api pelayan web anda. Had ini menjadikannya mencabar untuk menyekat akses mereka di peringkat rangkaian.
Menyekat Perplexity AI menggunakan fail robots.txt
Perkhidmatan lain yang menggunakan AI generatif untuk menulis semula kandungan anda ialah PerplexityBot. Untuk menyekat bot ini, anda boleh menambah peraturan berikut pada anda robots.txt file:
Ejen pengguna: PerplexityBot Tidak Benarkan: / Selain itu, PerplexityBot telah menerbitkannya Julat alamat IP, yang boleh anda sekat menggunakan Web Application Firewall (WAF) atau firewall pelayan web anda. Ini memastikan lapisan perlindungan tambahan terhadap akses tanpa kebenaran kepada kandungan anda.
Menyekat AI Anthropic (Claude)
Tambahkan baris berikut pada fail robots.txt anda:
Ejen pengguna: anthropic-ai Disallow: / Ejen pengguna: Claude-Web Disallow: / User-agent: ClaudeBot Disallow: /Bolehkah AI bot mengabaikan saya robots.txt fail?
Bolehkah AI bot mengabaikan saya robots.txt fail?
Organisasi yang mantap seperti Google dan OpenAI umumnya menghormati robots.txt protokol dan mematuhi peraturan yang anda tetapkan. Walau bagaimanapun, sesetengah bot AI yang direka dengan buruk atau berniat jahat boleh memilih untuk mengabaikan anda robots.txt fail sepenuhnya, memintas sekatan ini dan mengakses kandungan anda tanpa kebenaran.
Adakah Beretika untuk Menyekat Bot AI daripada Menggunakan Data Anda?
Dilema etika yang mengelilingi data latihan AI adalah kompleks. Walaupun AI sering dipromosikan sebagai alat untuk kebaikan manusia, membolehkan kemajuan dalam bidang seperti perubatan dan sains, ramai yang ragu-ragu tentang niat sebenar syarikat seperti OpenAI, Google atau Microsoft. Ada yang berpendapat bahawa teknologi ini lebih tertumpu kepada keuntungan daripada altruisme, terutamanya apabila AI generatif mula menggantikan pekerjaan kolar putih.
Perlu diingat bahawa pilihan untuk mengawal akses melalui robots.txt hanya tersedia selepas tindakan undang-undang daripada pengarang dan syarikat mencabar amalan ini di mahkamah. Akhirnya, melindungi kerja anda adalah keputusan peribadi, dan adalah penting untuk menimbang potensi manfaat dan risiko berkongsinya dengan sistem AI.