As a content creator or blog author, your unique, high-quality content is your asset. But have you noticed that some generative AI platforms, such as OpenAI and CCBot, might be using your work to train their algorithms—without your consent?
You don’t have to worry! By using a simple file called robots.txt, you can block these AI crawlers from accessing your website or blog.
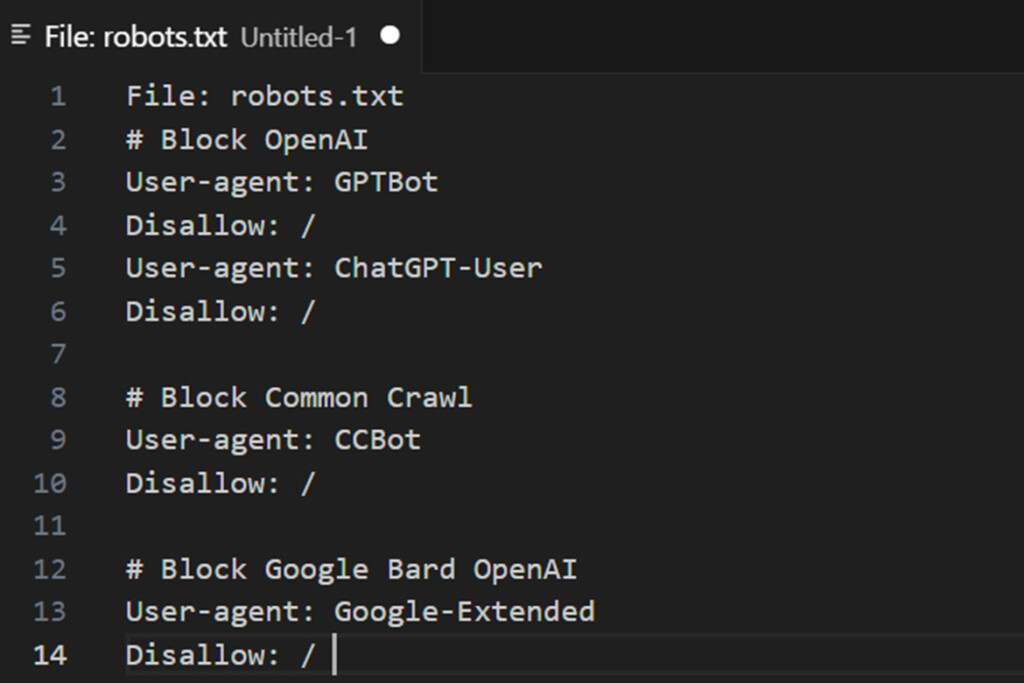
What is a robots.txt file?
The robots.txt file is a tool that allows website owners to manage how search engine crawlers interact with their content. It gives you the power to disallow specific bots from crawling your site, ensuring greater control over your content.
The syntax below shows how to block a single bot using a user-agent:
user-agent: {BOT-NAME-HERE}
disallow: /Below shows how to allow specific bots to crawl your website using a user-agent:
User-agent: {BOT-NAME-HERE}
Allow: /Where to place your robots.txt file?
Upload the file to your website’s root folder:
https://example.com/robots.txt
https://blog.example.com/robots.txtLearn More About robots.txt
If you’re ready to take control of your website’s accessibility, dive deeper into the details of robots.txt with these helpful resources:
- Introduction to robots.txt by Google: Understand the basics of how
robots.txtworks and how to configure it effectively for your site. - What is robots.txt? | How a robots.txt file works from Cloudflare: A comprehensive guide to the purpose and function of
robots.txtin managing web crawler access.
How to block AI crawlers bots using the robots.txt file
The syntax:
user-agent: {AI-Crawlers-Bot-Name-Here}
disallow: /Blocking Google AI (Bard and Vertex AI generative APIs)
Add the following two lines to your robots.txt:
User-agent: Google-Extended
Disallow: /Additional Information on User Agents and AI Bots
For more information about managing crawlers, you can review the list of user agents used by Google crawlers and fetchers. This can help you identify legitimate Google bots accessing your site.
However, it’s important to note that:
- Google does not provide CIDR, IP ranges, or ASN details for its AI bots, making it challenging to block them directly via your web server firewall.
- As a result, using a
robots.txtfile remains one of the most effective methods to guide compliant crawlers and restrict access to your content.
For advanced control, monitor your server logs for unusual activity and configure additional security measures, such as rate limiting or IP blocking, to complement your robots.txt directives.
Blocking OpenAI using the robots.txt file
Add the following four lines to your robots.txt:
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /OpenAI utilizes two distinct user agents for its operations: one for web crawling and another for browsing, each associated with unique CIDR and IP address ranges. Configuring firewall rules to block these requires an advanced understanding of networking concepts and root-level access to a Linux server.
If you’re not familiar with these technical aspects, such as managing CIDR ranges or configuring firewalls, it’s advisable to seek the assistance of a Linux system administrator. Keep in mind that OpenAI’s IP address ranges are subject to change, which can turn this process into an ongoing effort to keep up with updates—a game of cat and mouse.
1: The ChatGPT-User is used by plugins in ChatGPT
Below is a list of user agents used by OpenAI’s crawlers and fetchers, along with their associated CIDR or IP address ranges. To block OpenAI’s plugin AI bot, you can configure your web server firewall to restrict access from specific IP ranges, such as 23.98.142.176/28.
Here’s an example of how to block a CIDR or IP range using the ufw command or iptables on your server:
Using UFW:
sudo ufw deny from 23.98.142.176/28 Using iptables:
sudo iptables -A INPUT -s 23.98.142.176/28 -j DROP These commands prevent any traffic originating from the specified IP range from accessing your server. Make sure to review and update your firewall rules periodically to account for changes in OpenAI’s IP ranges. If you’re unfamiliar with configuring firewalls, consider enlisting the help of a Linux system administrator.
2: The GPTBot is used by ChatGPT
Below is a list of user agents used by OpenAI crawlers and fetchers, along with the associated CIDR or IP address ranges. You can block these ranges directly on your web server using either the ufw command or iptables.
Here’s an example shell script to block those CIDR ranges:
Shell Script to Block OpenAI CIDR Ranges
#!/bin/bash
# Purpose: Block OpenAI ChatGPT bot CIDR
# Tested on: Debian and Ubuntu Linux
# ------------------------------------------------------------------
file="/tmp/out.txt.$$"
wget -q -O "$file" https://openai.com/gptbot-ranges.txt 2>/dev/null
while IFS= read -r cidr
do
sudo ufw deny proto tcp from $cidr to any port 80
sudo ufw deny proto tcp from $cidr to any port 443
done < "$file"
[ -f "$file" ] && rm -f "$file"If you’re unfamiliar with firewall configuration, consult a Linux system administrator for assistance. Regularly update the script with new ranges to keep up with changes in OpenAI’s IP list.
Blocking commoncrawl (CCBot) using the robots.txt file
Add the following two lines to your robots.txt:
User-agent: CCBot
Disallow: /Common Crawl, a non-profit foundation, operates a bot called CCBot, which is widely used to collect data for training AI models. Blocking CCBot is also essential if you want to prevent your content from being utilized in this way. However, similar to Google, Common Crawl does not provide CIDR, IP address ranges, or autonomous system information (ASN) that can be used to block its bot through your web server firewall. This limitation makes it challenging to restrict their access at the network level.
Blocking Perplexity AI using the robots.txt file
Another service that uses generative AI to rewrite your content is PerplexityBot. To block this bot, you can add the following rule to your robots.txt file:
User-agent: PerplexityBot
Disallow: / Additionally, PerplexityBot has published its IP address ranges, which you can block using your Web Application Firewall (WAF) or web server firewall. This ensures an added layer of protection against unauthorized access to your content.
Blocking Anthropic AI (Claude)
Add the following lines to your robots.txt file:
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: ClaudeBot
Disallow: /Can AI bots ignore my robots.txt file?
Can AI bots ignore my robots.txt file?
Well-established organizations like Google and OpenAI generally respect the robots.txt protocols and comply with the rules you set. However, some poorly designed or malicious AI bots may choose to ignore your robots.txt file entirely, bypassing these restrictions and accessing your content without authorization.
Is It Ethical to Block AI Bots from Using Your Data?
The ethical dilemma surrounding AI training data is complex. While AI is often promoted as a tool for the betterment of humanity, enabling advancements in fields like medicine and science, many have doubts about the true intentions of companies like OpenAI, Google, or Microsoft. Some argue that these technologies are more focused on profit than altruism, especially as generative AI begins to replace white-collar jobs.
It’s worth noting that the option to control access through robots.txt only became available after lawsuits from authors and companies challenged these practices in court. Ultimately, protecting your work is a personal decision, and it’s important to weigh the potential benefits and risks of sharing it with AI systems.